Part of:Archive and backup: Protect data in the long term
Archive vs. backup and why you need to know the differences
Archiving and data backup are both key pieces of data protection. They can complement each other, but both provide distinct and important capabilities.
Backups are primarily used for operational recoveries, to quickly recover an overwritten file or corrupted database. Archives, on the other hand, typically store a version of a file that's no longer changing or shouldn't be changing.
Backup is not the same process as archiving. The two can complement each other, but in analyzing archive vs. backup, it's important to note their differences to avoid problems in recovery and retrieval down the line.
What is a backup?
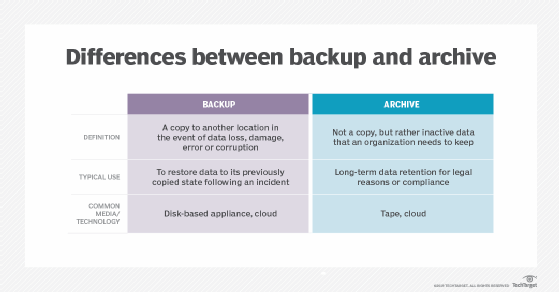
A data backup is a copy to another location for disaster recovery in the event of data loss, damage, error or corruption. An organization uses backup to restore data to its previously copied state following an incident. Common incidents for restoring from data backup include human error, natural disasters and cyberattacks.
One of the goals of backup is quick recovery. For the most critical data, backup should be performed on a device the organization can use to restore quickly, such as a disk-based appliance. For data restores that have a longer recovery time objective, an organization may use cheaper tape or cloud-based backups.
Depending on the organization and type of data, backups can be daily, hourly or even more frequent.
What is an archive?
Archiving is the process of moving data to another location for long-term retention. Unlike backup, archived data is not a copy, but rather inactive data an organization needs to keep. Reasons for archiving include legal regulations and compliance. Depending on the organization and type of original data, an archive may hold data for years. Archiving can also save an organization money by moving data off of a more costly primary storage device.
When comparing archive vs. backup, speed is less important in archives; even if the event is a legal action, you typically have a few days to respond. Searchability and indexing are more critical in archives as well. In addition, importance is placed on the ability to scale data integrity and Data retention over a long period of time, possibly decades. An archive is no longer limited to traditional files and images; most database applications have specific archive capabilities to allow the primary database to stay lean and fast while the archive is retained for research and compliance.
The two can complement each other, but in analyzing archive vs. backup, it's important to note their differences to avoid problems in recovery and retrieval down the line.
Email archiving applications are often the catalyst for establishing a separate archive process. It's important to realize that you are legally responsible to do more than just capture email.
While tape used to be a top data backup medium, it has taken on more of an archival role of late. With its strong durability, high capacity and low cost of storage, tapes can hold data safely and with minimal management for years. Tapes are inherently stored offline and so are safe from cyberthreats. Though it takes longer to retrieve data off of a tape than a disk, typical archive requests do not need to be fulfilled immediately. In fact, it's possible an organization will never have to access and retrieve certain data in an archive. In addition, the latest LTO tapes have indexing features and a write-once read-many capability that ensures archived data cannot be overwritten.
Just as disk became a popular addition to the backup process because of concerns about recovery from tape, data that's archived to tape can be vulnerable. There's a simple technology issue. Data on an LTO-5 tape from years ago may not be compatible with your latest tape drive, so you need to make sure you're able to read the data in your archives.
Disk is a long-term storage option, but it's costly. An organization may seek to store archived data on a disk for five to 10 years, but beyond that time frame, tape could be the better choice. The cloud is another potential medium for archival data. Major cloud providers including Amazon, Microsoft and Google offer cheaper options for that type of data. Though the cloud appears cheaper at first, it can get costly, depending on volume and length of time.
Differences between backup and archive
Archive vs. backup: Do you need both?
When considering combining archive and backup onto a single platform, the decision will depend on the specific platform, what the organization's retention requirements are and the expected goals of the archive vs. backup process.
While disk makes combining the process of backup and recovery into a single platform more realistic than tape, a best practice is to have a specific system for archives. Archives have different retention requirements, recovery needs and searchability requirements than backups.
Data backup is generally for short-term storage and recovery, while archives are for long-term storage and regulatory retention. Backups and archives are sometimes confused with each other, but they are not the same thing and offer different benefits.
Of late, there has been a move towards the convergence of backup and archive, as vendors and users see the two processes as complementary. That way the same IT administrator could manage both backups and the archival data. Some organizations use backup software for part or all of their archiving, as backup vendors have added archive features to their products. Maintaining separate architectures for archiving and backup can get expensive and time-consuming, especially for a small business that doesn't have a lot of resources.
Backup and archiving are two key elements of data protection.
Still, it's better to have separate processes for optimum data protection. Archiving products offer more capabilities and better features for archival data -- such as metadata search and e-discovery -- than backup software will generally provide. And backup media has features specific to protecting an organization's most critical data.