Inline deduplication vs. post-processing: Data dedupe best practices
Will inline or post-processing deduplication work better for your data protection platform? There are several products on the market that offer these capabilities.
Much of the early debate about data deduplication focused on inline deduplication vs. post-processing deduplication. Inline deduplication reduces redundant data before or while it is sent to the backup device; post-process backs up data first and then reduces it.
Deduplication is an effective way of conserving storage space by eliminating redundant data. While deduplication is typically categorized as either post-process or inline, there are also hybrid approaches.
Advantages and disadvantages
Both inline and post-process dedupe methods have their advantages and disadvantages.
Post-processing backs up data faster and reduces the backup window, but requires more disk because backup data is temporarily stored to speed the process.
Temporary storage space is not needed for inline deduplication. Inline deduplication is a popular option for primary storage on flash arrays, as it reduces the amount of data written to drives, reducing wear on the drives.
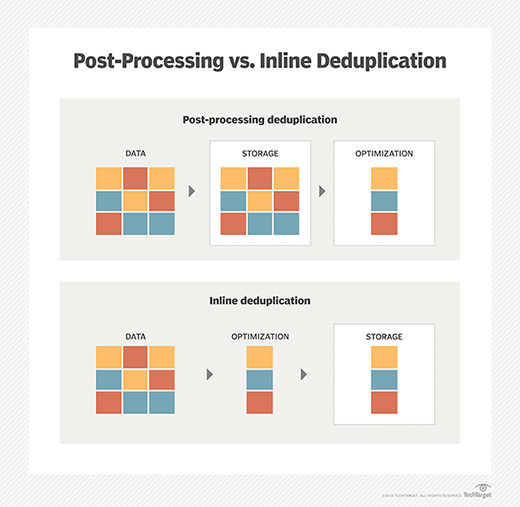
However, inline deduplication can cause a performance issue during the data backup process because the dedupe takes place between servers and backup systems.
Common deduplication products
Inline deduplication products include Dell EMC's Data Domain and Avamar, IBM Spectrum Virtualize, Veritas NetBackup, NEC HYDRAstor and Quantum DXi. Post-process products include ExaGrid EX. FalconStor and Hitachi Vantara offer customers the choice of post-process or inline dedupe.
FalconStor also has a method called concurrent processing because, while it moves data to a disk staging area first, it doesn't wait for backups to finish before deduping.
Deduplication used with other technologies
Both inline deduplication and post-process methods have their advocates, but experts say neither is universally better for data protection -- it all depends on what type of backup environment you have. You may also employ other techniques and technologies for optimum data protection.
Deduplication is often combined with replication for disaster recovery. While deduplication reduces the amount of duplicate data and lowers the bandwidth requirement to copy data off-site, replication copies data from one location to another, providing up-to-date information in the event of a disaster. Dell EMC, Quantum, IBM, FalconStor and Hitachi are among the vendors that have beefed up their replication capabilities, often increasing the number of remote sites that can fan into the data center.
In addition, erasure coding, compression and deduplication can work together in data protection and conserving storage capacity, but they have stark differences. Erasure coding enables data that becomes corrupted to be reconstructed through information about that data that's stored elsewhere. Compression reduces the number of bits needed to represent data.






