Videos
Photo Stories
-

5 of the hottest backup and recovery software startups to watch
-
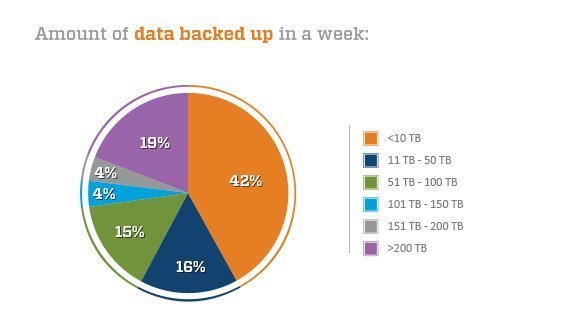
Backup challenges: Slow backup and recovery, growing capacity demands
Podcasts
-

Talking magnetic tape for storage with Quantum
-
Best backup and recovery tools cover cyber, all-in-one
-
Barracuda rep details natural disaster backup and recovery strategy
-
CEO details HYCU backup for hyper-converged, multi-cloud
-
Evolving data protection technologies require attention
-
Cloud-based backups aid overall data protection plan