Deduplication best practices and choosing the best dedupe technology
In our guide on deduplication best practices, learn how to choose the best dedupe technology, the differences between inline deduplication and post-processing, and more.
Data deduplication is a technique to reduce storage needs by eliminating redundant data in your backup environment. Only one copy of the data is retained on storage media, and redundant data is replaced with a pointer to the unique data copy. Dedupe technology typically divides data sets in to smaller chunks and uses algorithms to assign each data chunk a hash identifier, which it compares to previously stored identifiers to determine if the data chunk has already been stored. Some vendors use delta differencing technology, which compares current backups to previous data at the byte level to remove redundant data.
Dedupe technology offers storage and backup administrators a number of benefits, including lower storage space requirements, more efficient disk space use, and less data sent across a WAN for remote backups, replication, and disaster recovery. Jeff Byrne, senior analyst for the Taneja Group, said deduplication technology can have a rapid return on investment (ROI). "In environments where you can achieve 70% to 90% reduction in needed capacity for your backups, you can pay back your investment in these dedupe solutions fairly quickly."
While the overall data deduplication concept is relatively easy to understand, there are a number of different techniques used to accomplish the task of eliminating redundant backup data, and it's possible that certain techniques may be better suited for your environment. So when you are ready to invest in dedupe technology, consider the following technology differences and data deduplication best practices to ensure that you implement the best solution for your needs.
In this guide on deduplication best practices, learn what you need to know to choose the right dedupe technology for your data backup and recovery needs. Learn about source vs. target deduplication, inline vs. post-processing deduplication, and the pros and cons of global deduplication.
Deduplication Best Practices Guide: Choosing the right dedupe technology
Deduping can be performed by software running on a server (the source) or in an appliance where backup data is stored (the target). If the data is deduped at the source, redundancies are removed before transmission to the backup target. "If you're deduping right at the source, you get the benefit of a smaller image, a smaller set of data going across the wire to the target," Byrne said. source deduplication uses client software to compare new data blocks on the primary storage device with previously backed up data blocks. Previously stored data blocks are not transmitted. Source-based deduplication uses less bandwidth for data transmission, but it increases server workload and could increase the amount of time it takes to complete backups.
When you have large backup sets or a small backup window, you don't want to degrade the performance of your backup operation. For certain workloads, a target-based solution might be better suited.
Lauren Whitehousesenior analyst, Enterprise Strategy Group
Lauren Whitehouse, a senior analyst with the Enterprise Strategy Group, said source deduplication is well suited for backing up smaller and remote sites because increased CPU usage doesn't have as big of an impact on the backup process. Whitehouse also said virtualized environments are also "excellent use cases" for source deduplication because of the immense amounts of redundant data in virtual machine disk (VMDK) files. However, if you have multiple virtual machines (VMs) sharing one physical host, running multiple hash calculations at the same time may overburden the host's I/O resources.
Most well-known data backup applications now include source dedupe, including Symantec Corp.'s Backup Exec and NetBackup, EMC Corp.'s Avamar, CA Inc.'s ArcServe Backup, and IBM Corp.'s Tivoli Storage Manager (TSM) with ProtecTier.
target deduplication removes redundant data in the backup appliance -- typically a NAS device or virtual tape library (VTL). Target dedupe reduces the storage capacity required for backup data, but does not reduce the amount of data sent across a LAN or WAN during backup. "A target deduplication solution is a purpose built appliance, so the hardware and software stack are tuned to deliver optimal performance," Whitehouse said. "So when you have large backup sets or a small backup window, you don't want to degrade the performance of your backup operation. For certain workloads, a target-based solution might be better suited."
Target deduplication may also fit your environment better if you use multiple backup applications and some do not have built-in dedupe capabilities. Target-based deduplication systems include Quantum Corp.'s DXi series, IBM's TSM, NEC Corp.'s Hydrastor series, FalconStor Software Inc.'s File-interface Deduplication System (FDS), and EMC's Data Domain series.
Inline Deduplication vs. Post-processing Dedupe
Another option to consider is when the data is deduplicated. Inline deduplication removes redundancies in real time as the data is written to the storage target. Software-only products tend to use inline processing because the backup data doesn't land on a disk before it's deduped. Like source deduplication, inline increases CPU overhead in the production environment but limits the total amount of data ultimately transferred to backup storage. Asigra Inc.'s Cloud Backup and CommVault Systems Inc.'s Simpana are software products that use inline deduplication.
post-process deduplication writes the backup data into a disk cache before it starts the dedupe process. It doesn't necessarily write the full backup to disk before starting the process; once the data starts to hit the disk the dedupe process begins. The deduping process is separate from the backup process so you can dedupe the data outside the backup window without degrading your backup performance. Post-process deduplication also allows you quicker access to your last backup. "So on a recovery that might make a difference," Whitehouse said.
However, the full backup data set is transmitted across the wire to the deduplication disk staging area or to the storage target before the redundancies are eliminated, so you have to have the bandwidth for the data transfer and the capacity to accommodate the full backup data set and deduplication process. Hewlett-Packard Co.'s StorageWorks StoreOnce technology uses post-process deduplication, while Quantum Corp.'s DXi series backup systems use both inline and post-process technologies.
Content-aware or application-aware deduplication products that use delta-differencing technology can compare the current backup data set with previous data sets. "They understand the content of that backup stream, and they know the format that the data is in when the backup application sends it to that target device," Whitehouse said. "They can compare the workload of the current backup to the previous backup to understand what the differences are at a block or at a byte level." Whitehouse said delta-differencing-based products are efficient but they may have to reverse engineer the backup stream to know what it looks like and how to do the delta differencing. Sepaton Inc.'s DeltaStor system and Exagrid System Inc.'s DeltaZone architecture are examples of products that use delta differencing technology.
Global Deduplication
global deduplication removes backup data redundancies across multiple devices if you are using target-based appliances and multiple clients with source-based products. It allows you to add nodes that talk to each other across multiple locations to scale performance and capacity. Without global deduplication capabilities, each device dedupes just the data it receives. Some global systems can be configured in two-node clusters, such as FalconStor Software's FDS High Availability Cluster. Other systems use grid architectures to scale to dozens of nodes, such as Exarid Systems'DeltaZone and NEC's Hydrastor.
The more backup data you have, the more global deduplication can increase your dedupe ratios and reduce your storage capacity needs. Global deduplication also introduces load balancing and high availability to your backup strategy, and allows you to efficiently manage your entire backup data storage environment. Users with large amounts of backup data or multiple locations will gain the most benefits from the technology. Most of the backup software providers offer products with global dedupe, including Symantec NetBackup and EMC Avamar, and data deduplication appliances, such as IBM's ProtecTier and Sepaton's DeltaStor offer global deduplication.
As with all data backup and storage products, the technologies used are only one factor you should consider when evaluating potential deduplication systems. In fact, according to Whitehouse, the type of dedupe technologies vendors use is not the first attribute many administrators look at when investigating deduplication solutions. Price, performance, and ease of use and integration top deduplication shopper's lists, Whitehouse said. Both Whitehouse and Byrne recommend first finding out if your current backup product has deduplication capabilities. If not, analyze your needs long term and study the vendors' architectures to determine if they match your workload and scaling requirements.


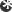 Source deduplication vs. target dedupe pros and cons
Source deduplication vs. target dedupe pros and cons 






