Docker
What is Docker?
Docker is an open source software platform used to create, deploy and manage virtualized application containers on a common operating system (OS), with an ecosystem of allied tools. Docker container technology debuted in 2013. At that time, Docker Inc. was formed to support a commercial edition of container management software and be the principal sponsor of an open source version. Mirantis acquired the Docker Enterprise business in November 2019.
Docker gives software developers a faster and more efficient way to build and test containerized portions of an overall software application. This lets developers in a team concurrently build multiple pieces of software. Each container contains all elements needed to build a software component and ensure it's built, tested and deployed smoothly. Docker enables portability for when these packaged containers are moved to different servers or environments.
How Docker works
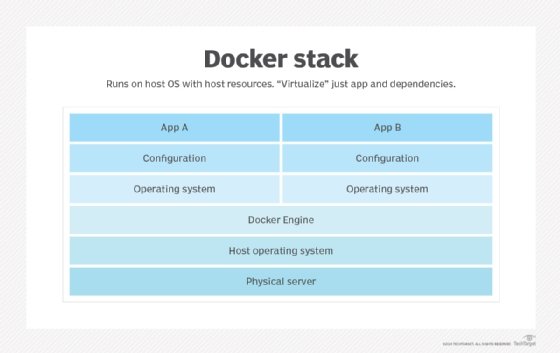
Docker packages, provisions and runs containers. Container technology is available through the operating system: A container packages the application service or function with all of the libraries, configuration files, dependencies and other necessary parts and parameters to operate. Each container shares the services of one underlying OS. Docker images contain all the dependencies needed to execute code inside a container, so containers that move between Docker environments with the same OS work with no changes.
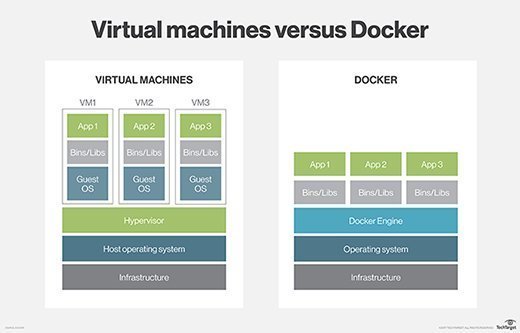
Docker uses resource isolation in the OS kernel to run multiple containers on the same OS. This is different than virtual machines (VMs), which encapsulate an entire OS with executable code on top of an abstracted layer of physical hardware resources.
Docker was created to work on the Linux platform, but it was extended to offer greater support for non-Linux OSes, including Microsoft Windows and Apple OS X. Versions of Docker for Amazon Web Services (AWS) and Microsoft Azure are available.
Key use cases for Docker
While it's technically possible to use Docker for developing and deploying any kind of software application, it is most useful to accomplish the following:
- Continuously deploying software. Docker technology and strong DevOps practices make it possible to deploy containerized applications in a few seconds, unlike traditional bulky, monolithic applications that take much longer. Updates or changes made to an application's code are implemented and deployed quickly when using containers that are part of a larger continuous integration/continuous delivery pipeline.
- Building a microservice-based architecture. When a microservice-based architecture is more advantageous than a traditional, monolithic application, Docker is ideal for the process of building out this architecture. Developers build and deploy multiple microservices, each inside their own container. Then they integrate them to assemble a full software application with the help of a container orchestration tool, such as Docker Swarm.
- Migrating legacy applications to a containerized infrastructure. A development team wanting to modernize a preexisting legacy software application can use Docker to shift the app to a containerized infrastructure.
- Enabling hybrid cloud and multi-cloud applications. Docker containers operate the same way whether deployed on premises or using cloud computing technology. Therefore, Docker lets applications be easily moved to various cloud vendors' production and testing environments. A Docker app that uses multiple cloud offerings can be considered hybrid cloud or multi-cloud.
Docker architecture: Components and tools
Docker Community Edition is open source, while Docker Enterprise Edition is a commercialized version offered by Docker Inc. Docker consists of various components and tools that help create, verify and manage containers.
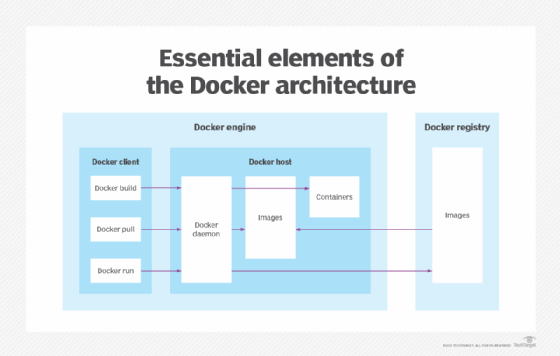
The Docker Engine is the underlying technology that handles the tasks and workflows involved in building container-based applications. The engine creates a server-side daemon process that hosts images, containers, networks and storage volumes.
The daemon also provides a client-side command-line interface (CLI) for users to interact with the daemon through the Docker application programming interface. Containers created by Docker are called Dockerfiles. Docker Compose files define the composition of components in a Docker container.
Other components and tools in the docker architecture include the following:
- Docker Hub. This software-as-a-service tool lets users publish and share container-based applications through a common library. The service has more than 100,000 publicly available applications as well as public and private container registries.
- Trusted Registry. This is a repository that's similar to Docker Hub but with an extra layer of control and ownership over container image storage and distribution.
- Docker Swarm. This is part of the Docker Engine that supports cluster load balancing for Docker. Multiple Docker host resources are pooled together in Swarm to act as one, which lets users quickly scale container deployments to multiple hosts.
- Universal Control Plane. This is a web-based, unified cluster and application management interface.
- Compose. This tool is used to configure multicontainer application services, view container statuses, stream log output and run single-instance processes.
- Content Trust. This security tool is used to verify the integrity of remote Docker registries, through user signatures and image tags.
Docker versions and major features
Docker Enterprise 1.13, released in January 2017, added backward compatibility for the CLI to handle older Docker daemons, and several Docker commands to manage disk space and data more efficiently. Some security and bug fixes were also added.
Other improvements to Docker Enterprise in 2017 included native Kubernetes support for container orchestration in addition to Docker's Swarm mode. Support for IBM mainframe and Windows Server 2016 was also added for users to run mixed clusters and applications across multiple operating systems.
Docker Enterprise Edition 2.0, released in April 2018, featured multi-OS and multi-cloud support for hybrid environments.
Docker Enterprise 3.0, released in 2019, added blue-green container cluster upgrades and the ability to build multiservice container-based applications run from any environment. Other new features included the following:
- Docker Desktop Enterprise, which lets developers deploy applications to a Kubernetes-conforming environment with automated pipeline integration and centralized IT management.
- Docker Applications, a set of productivity tools for developers.
- Docker Kubernetes Service, which automates management and scale of Kubernetes-based apps and provides security, access control and automated lifecycle management.
- Docker Enterprise as a Service, a fully managed enterprise container service.
Docker advantages and disadvantages
Docker emerged as a de facto standard platform to quickly compose, create, deploy, scale and oversee containers across Docker hosts. In addition to efficient containerized application development, the other benefits of Docker include the following:
- A high degree of portability so users can register and share containers over various hosts.
- Lower resource use.
- Faster deployment compared to VMs.
There are also potential challenges with Docker:
- The number of containers possible in an enterprise can be difficult to manage efficiently.
- Container use is evolving from granular virtual hosting to orchestration of application components and resources. As a result, the distribution and interconnection of componentized applications -- which can involve hundreds of ephemeral containers -- is becoming a major hurdle.
In recent years, Docker was supplanted by Kubernetes for container orchestration. However, most Kubernetes offerings actually run Docker behind the scenes.
Docker security
A historically persistent issue with containers -- and Docker, by extension -- is security. Despite excellent logical isolation, containers still share the host's operating system. An attack or flaw in the underlying OS can potentially compromise all the containers running on top of the OS. Vulnerabilities can involve access and authorization, container images and network traffic among containers. Docker images may retain root access to the host by default, although this is often carried over from third-party vendors' packages.
Docker has regularly added security enhancements to the Docker platform, such as image scanning, secure node introduction, cryptographic node identity, cluster segmentation and secure secret distribution. Docker secrets management also exists in Kubernetes as well as CISOfy Lynis, D2iQ and HashiCorp Vault. Various container security scanning tools have emerged from Aqua Security, SUSE's NeuVector and others.
Some organizations run containers within a VM, although containers don't require virtual machines. This doesn't solve the shared-resource problem vector, but it does mitigate the potential impact of a security flaw.
Another alternative is to use lower-profile or "micro" VMs, which don't require the same overhead as a typical VM. Examples include Amazon Firecracker, gVisor and Kata Containers. Above all, the most common and recommended step to ensure container security is to not expose container hosts to the internet and only use container images from known sources.
Security was also the main selling point for Docker alternatives, particularly CoreOS' rkt, pronounced rocket. However, Docker has made strides to improve its security options while, at the same time, momentum for those container alternatives has faded.
Docker alternatives, ecosystem and standardization
There are third-party tools that work with Docker for tasks such as container management and clustering. The Docker ecosystem includes a mix of open source projects and proprietary technologies, such as open source Kubernetes; Red Hat's proprietary OpenShift packaging of Kubernetes; and Canonical's distribution of Kubernetes, referred to as "pure" upstream Kubernetes. Docker competes with proprietary application containers such as the VMware vApp and infrastructure abstraction tools, including Chef.
Docker isn't the only container platform available, but it's still the biggest name in the container marketplace. CoreOS rkt is noted for its security with support for SELinux and trusted platform management. Red Hat, now owned by IBM, purchased CoreOS and integrated its functionality into its OpenShift architecture. However, rkt is now an archived project at the Cloud Native Computing Foundation.
Other major container platforms include OpenVZ, the oldest of the system container platforms originally developed by Virtuozzo. OpenVZ combines the small size and high speed of standard containers with the additional security of an abstracted OS layer.
Docker also played a leading role in an initiative to more formally standardize container packaging and distribution named the Open Container Initiative, which was established to foster a common container format and runtime environment. More than 40 container industry providers are members of the Open Container Initiative, including AWS, Intel and Red Hat.
Finally, Windows Server 2019 and Windows 10 offer direct support for containers using the Windows container feature based on Docker technology.
Docker company history
Docker was first released as an open source platform in March 2013 under the name dotCloud. Docker Engine 1.0 launched in 2014. In 2016, Docker integrated its Swarm orchestration with Docker Engine in version 1.12. Docker's broader goal was to build up its business with containers as a service, but eventually, these plans were overtaken by the rise of Kubernetes.
Docker Enterprise was introduced in March 2017. The company also donated its "containerd" container runtime utility to the Cloud Native Computing Foundation that year.
In November 2019, Mirantis acquired Docker products and IP around Docker Engine. The acquisition included Enterprise, Docker Trusted Registry, Docker Universal Control Plane and Docker CLI as well as the commercial Docker Swarm product. Mirantis initially indicated it would shift its focus to Kubernetes and eventually end support for Docker Swarm but later reaffirmed its intent to support and develop new features for it. The remaining Docker Inc. company now focuses on Docker Desktop and Docker Hub.
Since 2021, Docker's Desktop service is no longer available for free use for enterprises. Enterprise use of Desktop requires a paid subscription plan. However, a free version is available to individuals and small businesses.




