
data restore
What is data restore?
Data restore is the process of copying backup data from secondary storage and restoring it to its original location or a new location. A restore is performed to return data that has been lost, stolen or damaged to its original condition or to move data to a new location.
Several circumstances lead to the need for a data restore. One is human error, where data is accidentally deleted or damaged. Other circumstances include malicious attacks where data is exposed, stolen or infected; power outages; human-made or natural disasters; equipment theft, malfunctions or failures; or firmware corruption.
Data restore makes a usable copy of the data available to replace lost or damaged data and ensures the data backup is consistent with the state of the data at a specific point in time before the damage occurred.
Types of data loss and hardware damage
Data restore operations are almost always initiated in response to a data loss event. Such events, however, vary in scope. There are any number of circumstances that can lead to data loss, including the following:
- Human error. In the case of file data, for example, a user might accidentally delete a file or overwrite important data within a file.
- File system corruption. File system corruption can render data files unreadable. It can also break the structure. Corruption can also occur within databases, such as those used to store big data or machine learning data.
- Malicious activities. A disgruntled user, for instance, might delete or password-lock some of the organization's most sensitive data. Similarly, data loss might occur if data becomes encrypted by ransomware or infected with a virus.
- Hardware failures. If enough disks within a storage array were to simultaneously fail, for instance, data loss occurs. Similarly, a disk controller can fail in a way that results in corrupt data being written to a storage array.
- Physical disasters. An organization's data center might be destroyed by fire or flood.
The best way for an organization to avoid losing data as a result of these types of events and to ensure business continuity is to create a comprehensive backup strategy that's designed to create backup copies of its data. Backups can be written to a backup device residing on premises, to cloud storage, to tape drives or even to an external drive. Regardless of the medium, it's important to ensure data is being backed up. After all, initiating a restore operation is impossible if there's no backup data to restore.
Preparing for a data restore
Data restoration is part of the overall data management process and is contingent on having a system in place to produce a good copy of the data being protected by traditional backup, snapshots or continuous data protection (CDP). Without a reliable protection copy, there's nothing usable to restore.
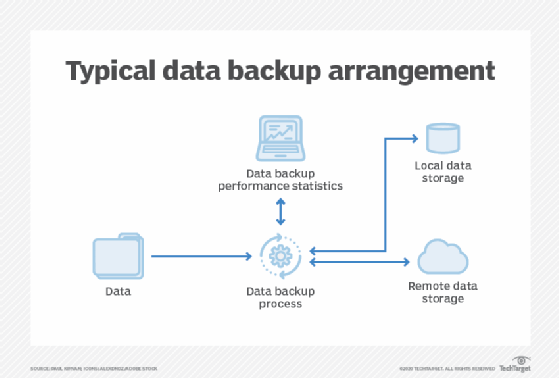
When preparing for data restoration, an organization should consider the following points:
- Data backup strategy. A person or organization should establish a comprehensive data backup strategy that defines which data needs to be backed up, how frequently backups should be performed and where the backups will be stored. Using a combination of local backups as well as off-site or cloud-based backups should be considered for added protection.
- Backup testing. To ensure a reliable data backup version is available to restore, it's necessary to test the restore process and the data restore tools used.
- Define RPO and RTO. Recovery point objective (RPO) is the longest period that can be tolerated between data losses, whereas recovery time objective (RTO) represents the longest period of acceptable downtime following a data loss incident. Data being restored must be readable, be consistent with a chosen point in time, and include the information needed to comply with the RPO and RTO.
- Random checks. Protection copies should be randomly checked at various points in time to ensure they meet both the RPO and RTO.
- Test data restore procedure. All applications must be checked before doing an actual data restore to ensure they can use the restored data. That means the software used to format the data must be available, and security certificates, permissions, access control and decryption must be applied correctly.
Methods of restoring data
Where backup data is stored affects the ease with which it can be restored. Some common backup locations include the following:
- HDD backups. HDD, or hard disk drive, backups provide a quick data restore because it's easy to locate data on disks, and the systems often live on site. For this same reason, HDDs are more secure than off-site tape and cloud backup. However, disk systems cost more than other data backup and restore methods; costs include the power needed to run both the disk systems and the cooling systems they require. HDD backups are best for data that changes frequently and requires a short recovery time.
- Tape backup. Tape backup systems provide high-capacity storage at a lower cost than HDDs. But even with the latest technology, tape still has a longer recovery time than disks or the cloud, and that time frame expands when data is stored off site. Tape libraries require ongoing management and testing to ensure data is accessible when needed.
- Cloud backup. Cloud backup requires enterprises to send a copy of data over the corporate network or the internet to an off-site server owned by the enterprise or hosted by a service provider. When it's time to restore that data, it must traverse the same path, which can take time due to network bandwidth limitations. For this reason, cloud backup and restore is generally used for noncritical data. With cloud backup, it's easy to add capacity as data backup needs grow. In addition, costs are lower, particularly when using a cloud provider, because organizations don't have to buy and maintain backup software and hardware. Using a third-party provider also reduces the IT department's workload. However, as data volumes grow, cloud backup costs rise.
Data restore techniques
The approach used to restore data depends on what information was lost or damaged, how much data was affected, how the incident happened, the software used to create the data backup, the backup target media and other factors. Some backup software lets users restore lost files themselves. Data recovery software and services can retrieve accidentally deleted files that aren't backed up from the hard drive.
More complicated data loss or damage requires IT to restore backup files from disk, tape or other backup media using various techniques, including the following:
- Instant recovery, also known as recovery in place, redirects a user's workload to a backup server, eliminating the recovery window. Users get almost immediate access to a snapshot restore point of their workload, where they can work while IT manages the full recovery and data restore in the background. Once that process is complete, the user's workload is redirected back to the original virtual machine.
- Replication provides even faster, near-instant access to data; however, data backup with integrated replication often lacks a product that provides historical recovery and isn't a true backup capability.
- CDP, or continuous data protection, is when data is backed up using snapshots taken every time the data changes. This approach lets data be rolled back to any point in time; however, it comes at a price because it can tax a system's central processing unit and require a lot of storage to accommodate heavily updated data.
- Near-CDP is when snapshots of changed data are taken at set intervals and changes are then consolidated over a longer period. This approach reduces the total amount of storage required to accommodate backed-up data compared with full-fledged CDP.
- Traditional backup is when data is stored on HDDs or magnetic tape either locally or at a remote location. Traditional backup is most useful when a major hardware or site disaster occurs. It lacks the scalability and efficiency of other methods, but it's a better long-term approach for data retention and restoration.
Mobile backup and restore
Backing up and restoring mobile data from smartphones, tablets and laptops poses specific challenges. Traditional backup software often assumes that devices being backed up have a permanent location, a consistently good connection to the corporate network and adequate bandwidth. But mobile devices frequently don't have access to these capabilities.
Enterprise file sync and share (EFSS) services protect data on mobile devices by copying files to the cloud or on-premises storage. EFSS lets users access these files on other desktop and mobile devices, but it's not a true backup and doesn't allow for the rollback of data to a particular point in time should the device fail, if the device is lost or stolen, or if data on it is damaged or destroyed.
Most Android devices and all Apple iOS devices have native, image-based backup, but that leaves the responsibility for backing up these devices with users. An endpoint backup product that supports mobile devices and incorporates file sync and sharing is one way to handle this. As with all enterprise data backup and data restore procedures, the key to smooth data restoration on mobile devices is to have a consistent, tested backup process and data recovery tools in place so that data can be restored quickly and easily when necessary.
Typical scenarios where mobile backups can be helpful include the following:
- When a mobile device is replaced. Mobile backups make it easy to transfer backed-up data from an old device to a new one.
- When the data on a mobile device is lost or stolen. In case of accidental loss or deletion of data, it can be restored back to the latest backup.
- When a mobile device is reset. If a mobile device is reset to a factory install, the data that's backed up can be used to restore the device to its previous state.
- When a mobile device is infected with malware and viruses. After the infection is removed, the mobile device can be restored to the original settings with the latest backup.
Data restore vendors and products
Numerous backup vendors offer products for backing up and restoring an organization's data. These products vary widely in terms of price, scope and capabilities. Examples of the available products include the following:
- Acronis Cyber Protect.
- Arcserve Unified Data Protection.
- Carbonite.
- Cohesity DataProtect.
- Commvault Backup and Recovery.
- IBM Spectrum Protect.
- NetApp SnapCenter.
- Rubrik Security Cloud.
- Veeam Backup & Replication.
- Vembu BDRSuite.
- Veritas Backup Exec.
- Zerto.
Preparation is vital to prevent data loss and resume operations quickly and efficiently after a natural disaster. Learn how to perform critical backups and prevent data loss.






