
full backup

What is a full backup?
A full backup is the process of making at least one additional copy of all data files that an organization wishes to protect in a single backup operation. The files that are duplicated during the full backup process are designated beforehand by a backup administrator or other data protection specialist. Typically, the data that is copied comprises files used by applications, some metadata that helps make the files more useful to the applications, logs and tracking files that document what the applications are processing as well as other control and management files.
Generally, applications, operating systems and other software aren't copied during a full backup. Those bits and bytes might well be needed for disaster recovery, but other techniques, such as disk mirroring or disk cloning are used to copy those key elements.
Data backup software controls the full backup process and enables specialists managing the process to designate which volumes and files should be copied and the backup destination, or the specific media that the data will be copied to. Most backup software will maintain a catalog that indicates what was backed up when, to where and whether the process completed successfully.
Types of backups
A full backup is one of four popular backup methods. The four data backup types are:
- Full backups
- Differential backups
- Incremental backups
- Disk mirroring
Each type will be explained further and compared to a full backup later in this definition.
When to perform a full backup
Early in the development of data processing, most data backups were full backups, often quite simply the process of recalling and copying data to another tape. But as hard drives and, later, solid state storage devices came into use, the amount of data that could be processed and stored grew rapidly, making daily full backups impractical as they could not be completed in the backup window that is roughly defined as the hours between a business closing for the day and reopening the following morning.
This article is part of
What is cloud backup and how does it work?
Rather than being the essential and sole process of a daily data protection scheme, full backups have evolved into one of multiple key factors for effective data protection strategies. Relying on daily full backups is not a practical approach, but less frequent full backups provide the core data for a number of other, less time consuming backup methodologies.
For example, a weekly full backup coupled with incremental or differential daily backups is practical for most companies -- even if the amount of data that must be protected is voluminous. Regardless of the daily backup method employed, at some point a baseline full backup is necessary to ensure that all data is duplicated. So although the practice of doing daily fulls is unrealistic for most companies, at some point a full backup is required to support other backup procedures. Other situations that might require a full backup include prior to installing new software or upgrading an operating system.
What are the advantages of full backups?
A full backup is often considered the most secure, reliable method of copying data. A few additional advantages include:
- Restore and recovery times are shorter because complete data is always readily available.
- All data is backed up at once, making version control easy to manage.
- Backup files are easier to locate as they are all kept on the same storage medium.
What are the disadvantages of full backups?
However, there is a trade-off with full backups and some disadvantages to the strategy are:
- Higher bandwidth and more storage space is required.
- Can be time-consuming to perform depending on the amount of data being backed up.
- Backups can become redundant as unaltered files continue to be copied repeatedly.
- If the copy of the data is leaked or compromised, the entire backup repository can be stolen.
Example of a full backup
In order to perform a full backup, the admin in charge of overseeing the process must designate which files need to be copied and enforce a backup schedule. For example, the admin might determine that a specific hard disk needs to execute a full backup twice a week, on Tuesdays and Fridays. On Tuesday, the entire directory of folders and files on that drive will be copied. On Friday, any new files added to that drive will be copied and all the existing directory from before will be copied again.
Full backup and disaster recovery
A successful full backup will ensure that the data needed to recover from a disaster is available. But an overall disaster recovery strategy might also require procedures such as rebuilding servers, reinstalling operating systems and application software and restoring drivers, ancillary files and data elements. For effective disaster recovery, those systems files and components also must be copied to other equipment, preferably at a remote site. That part of the data protection process is usually performed as a separate operation that will ensure that when the full backup data is required, the proper environment has been recreated remotely and is ready to accept the data and operate as near to normal as possible until the primary servers and storage systems are once again available.
So although a full backup of data is usually required for disaster recovery, it isn't the only piece that is needed to successfully recover from a disaster. Fortunately, for most companies the need to enact a disaster recovery process is a rare event, so full backups are less frequently called on for a full restoration of the full data set than they are for random, smaller scale data recoveries. These recoveries of single files or volumes might be required after an accidental deletion or damage to a file or set of files and are referred to as operational recoveries.
Full backup vs. incremental backup
A differential backup procedure is like the full backup plus incremental backup process, but it might save some time if large or full data recovery is required.
Incremental backups copy only the data that is new or has been changed since the previous backup event. Therefore, an incremental will copy far less data and will make it more likely that the backup process can be completed without exceeding the limits of the backup window.
For example, a full backup of all data might be completed over the weekend. At the end of the day on Monday, an incremental backup will record all the new or changed data from that day as compared to the full backup from the weekend. On Tuesday, another incremental backup will be run and it will capture and copy all the new and changed data from that day. This process will continue daily until the next full backup is performed.
When data needs to be recovered from a full plus incremental backup system, the backup software must assemble an up-to-date backup data set by applying each incremental in reverse order and applying all of the changes and additions to the initial full backup. If the full backup must be recovered, the process of creating a current and complete full data set can take some time.
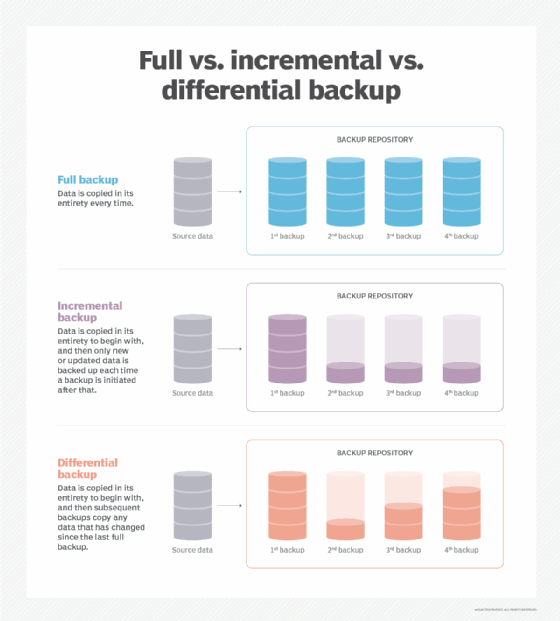
Full backup vs. differential backup
A differential backup procedure is similar to the full backup plus incremental backup process, but it might save some time if a large or full recovery is required.
With full backup plus differentials, the way a recoverable full copy of the protected data is created differs from the simple cumulative process that is used with incrementals. The differential backup approach also starts with a full backup of all data to be protected and, as with incrementals, for the first backup after the full only new and changed data is copied. But rather than just holding onto the changed data backup until a recovery is needed, the differential method effectively creates new fulls for each changed data backup event.
That means that if a full backup must be recovered -- or even if a partial recovery is required -- a copy is always available.
Full vs synthetic full
The term synthetic full backup or simply synthetic backup is often used to describe the outcome of the process where incrementals or differentials are used in conjunction with a “real” full backup to create an updated full backup copy of data.
The data in a current synthetic full backup is identical to that of a current full backup, but it is derived by applying the periodic incrementals or differentials to the base full backup. The nomenclature is merely an indication of how a full backup was created, but in either case, the backed-up data is complete.
Full backup vs. disk mirroring
Although the terms full backup and disk mirroring might suggest that they are accomplishing the same thing, the processes and results might be very different. As noted, a full backup comprises a copy of data that must be protected, but it usually does not include operating systems, related files and application software. Mirror backup, on the other hand, creates an exact replica of a source drive which will often include the server OS and applications.
The differences are important particularly for disaster recovery operations, rather than routine operational recoveries. Recovering a full backup will ensure that the data needed to recover from a disaster is available, but it will likely lack the necessary components to start up servers and storage systems at a remote location. A disk -- or drive -- mirror often includes those elements, so it's relatively easy to spin up servers and storage to run business operations from the remote facility.
Full backup vs. snapshots and replication
Snapshots are very similar in concept to incremental backup copies, but compared to incrementals, snapshots offer some additional benefits and a few limitations as well.
Snapshots capture changes to data sets and store that information as a set of pointers based on a reference, or full, copy of the data. Snapshots can occur frequently, enabling users to rewind back to a particular date and time to recover data. This ability can be beneficial if any files are damaged or infected with a virus as the storage system admin can go back to a time before the corruption occurred and recover a clean set of data.
Snapshotting software is typically proprietary to the particular storage system vendor which means it might not be possible to collect or combine snapshots from different storage systems. Also, snapshots are "internal" processes, meaning that the snapshots are stored on the same system as the source data. To use snapshots as a backup, they must be moved to a separate system by a process called Replication, which will make them available if the source system or data fails.
Full backup and continuous data protection
Continuous data protection (CDP) is another method of creating timely and comprehensive backup copies. As with other backup approaches, CDP relies on a full backup as the basis of its operation. CDP is like incremental backups, but the CDP process doesn't wait until the end of the day to gather and store the changes to the latest full backup. Rather, true CDP captures the changes as they happen -- or at least as they are committed to storage -- and applies them to update the full backup.
Theoretically, CDP should eliminate the need for daily backups and should thus effectively shut the backup window. However, CDP isn't practical for all applications, especially those that update large amounts of data frequently. In those cases, the CDP process would likely require too much processing power and other resources, draining performance from the applications. Near CDP is an offshoot of CDP and, as its name suggests, doesn't capture changes continuously, but rather periodically to lessen its processing requirements.
Full backups in the world of cloud backup
Given the large amounts of data they must process and maintain, many companies today rely on cloud backup services to protect their data rather than hosting the entire backup environment internally. But even within a cloud backup scenario, full backups play a key role.
For cloud backups to provide effective data protection, they must host the latest full copy of a company’s data. Of course, that amount of data might be voluminous and getting it from the corporate data center to the cloud backup service provider over a telecommunications line can be problematic. To avoid what would be a long, very slow data transmission process, cloud service providers offer customers the ability to seed their backup data in the cloud by sending a full backup copy of their data to the cloud service on some form of physical media. The cloud service can then transfer that data to their system using a fast copy or replication process.






