
Fotolia
Everything you need to know about snapshotting
Though backups are a core element of a basic data protection strategy, Jason Buffington explains why storage snapshots and replication are must-haves as well.

You've probably heard the mantra that snapshots aren't backups. That's true, of course, but snapshots are increasingly playing a role in modern data protection. According to Enterprise Strategy Group data, nine out of 10 organizations use storage-centric protection technologies -- snapshotting or replication -- to supplement backups in highly virtualized environments nowadays.
While backups continue to underpin every organization's data protection strategy, snapshots are often a complementary approach for ensuring the reliable protection and rapid recovery of IT infrastructure. Furthermore, snapshots are -- alongside replication -- the foundation for modern data protection.
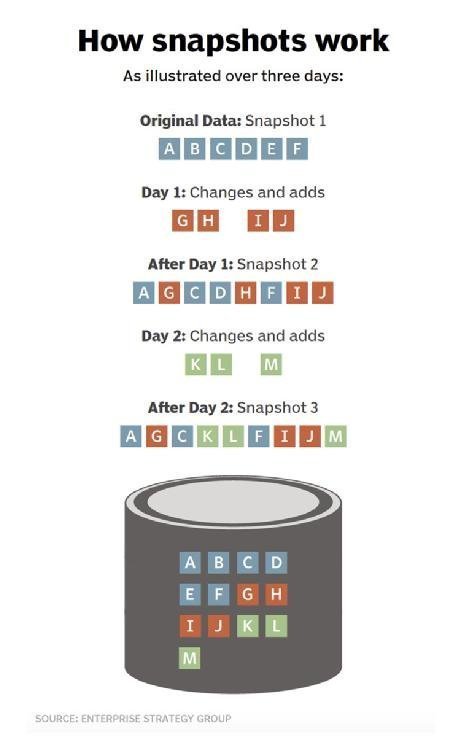
How snapshots work
Although the granular details can vary slightly, snapshots are essentially collections of disk blocks that represent what a file system or volume looked like at a specific point in time. Regardless of the application, virtualization tier or other abstraction layer, almost all storage offerings can be boiled down to a file system where individual files and folders are actually made up of related chunks of data held within disk blocks on the storage system itself. To be clear, these may be physical blocks within a storage array or virtualized blocks within a software-defined storage or virtual appliance platform. The key to accessing your files, folders and data is a disk map, pointing to the blocks themselves, that resides immediately below your file system of choice.
Simply put, presume a 75 KB file has its data spread across three 32 KB disk blocks. All higher-layer access methods -- including file information, attributes and metadata, and application relevance -- are contained in a file system driven by an operating system that offers the file as structured or unstructured data. The file system itself merely contains an entry to the "file" and sequential pointers to the three disk blocks, which are randomly spread across the actual storage medium. You can think of a snapshot as the "frozen" contents of those three blocks, along with the metadata and pointers.
Perhaps the middle of the file changes later. Underneath the file system, the first and third blocks remain, but the second block now contains new data. The process of snapshotting retains copies of the blocks so the file can be "reverted" to a previous point in time by simply reconnecting the three original blocks of data. In full disclosure, snapshots almost always occur at a volume level, not a file level as the example above describes. This explanation is applicable to both, however, and can be better understood via "How snapshots work" below.
Why snapshots matter
According to ESG research, 67% of servers have a downtime tolerance of less than two hours, as shown in "Downtime tolerance surveyed."
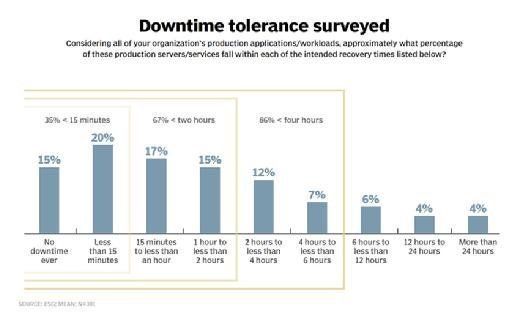
While backup systems can often handle two hour-plus recoveries, only one in seven servers tolerates the six hour-plus downtime windows forced by legacy backup mechanisms. And because backups transform data to a more easily compressible and storable state on alternative hardware or services than where the original data resides, there are some practical limits to even the fastest restorations from backup. Alternatively, reversion to a previous snapshot is measured in minutes, or less, since the blocks reside within the same array as the primary data. While reversions from snapshots may sound definitively better than recoveries from backups, there are a few common trade-offs:
- Local vulnerability. While backups are, by definition, copies held elsewhere, snapshots reside within the same storage as the production data. If the production array is hindered, the snapshots will be unavailable.
- Storage consumption. Somewhat relatedly, while backups often use a different class of storage for their repositories, snapshots invariably consume capacity, at a premium, within the production environment's high-performance storage systems.
- Protection frequency. Because of the premium storage consumption, most organizations will retain data within snapshots for days only, compared to months or years for backups. That said, you can often take snapshots during the day -- every few hours or down to every 15 minutes -- compared to far less frequent and typical nightly backup operations.
With such significant trade-offs when employing snapshots, most organizations should use snapshots for what they are best at -- near-immediate recoverability of relatively recent data -- and then treat backups (even from disk) as the second option for recoveries. They should also combine snapshotting with backups to ensure data is survivable outside of the array for a significantly longer period of time.
Differentiating snapshot mechanisms
One differentiable characteristic among snapshotting methods is Copy-On-Write (CoW) versus redirect-on-write (RoW), essentially referring to how disk blocks behave when new data is written.
Let's refer to the earlier example:
- A file requiring three disk blocks is written to blocks A, B and C.
- A snapshot is invoked, likely due to a policy in the storage UI or a backup application that integrates with the storage array.
- The file is updated, requiring the replacement of information within the middle of the logical file.
If copy-on-write is used by the storage system, the following will occur:
- The contents of disk block B are copied somewhere else on the volume -- new block "D."
- The updated file data is written into existing block B -- overwriting the initial data which has now been preserved elsewhere.
- By writing the new data into block B, the three blocks can be accessed sequentially (ABC).
Alternatively, if redirect-on-write is used by the storage system, expect the following:
- The new data is immediately written to new block D.
- The pointers within the file system now indicate that the file is composed of blocks "ADC," with original block B retained as-is for the snapshot.
By redirecting the changes to a new block, no additional I/O operations have to occur in the storage system during production use.
Historically, extra I/O led to significant fragmentation, causing some storage systems to perform reclamation or reorganization tasks -- especially when file systems were held on single arrays (e.g., personal computers versus multispindle arrays). In both the CoW and RoW examples, when the snapshot retention window has expired (e.g., 72 hours, by which time at least one backup has occurred), the disk system reclaims blocks (D in CoW, B in RoW) as free space and the snapshot pointers vanish.
How to gain more from snapshots
Two common capabilities enabled from snapshotting include clones and transportable snapshots.
- Cloning, offered under a variety of branded terms, typically refers to using snapshot functionality for purposes other than data recovery. Many organizations want copies of their data for application development, patch testing, reporting and analytics, and so on. But they can't afford all of the incremental storage to house disparate copies -- nor want to incur the I/O penalty to transmit all of that data from the production systems. Instead, because snapshots are literally pointers to blocks, those pointers can often be exposed as a second file system (i.e., a clone) without taking up any additional storage capacity. While production users continue to access live data, developers, analysts and other beneficiaries can access the clone for their purposes, assuming that the storage array can ensure enough IOPS so as not to hinder the production environment. While new data might consume a slight amount of incremental storage, it is typically temporary and far less involved than making an entire new copy of the data set.
- Replication of blocks, though technically not part of the snapshot, per se, is often touted by vendors as more efficient than the file-based replication technologies performed by higher-level functions. It is often the same underpinning technologies within the storage product that manage the block functionality that are either knit together as snapshots or transmitted for replication.
- Transportable snapshots utilize the block-based replication of some arrays, but also replicate the metadata and pointers necessary for reconstituting the same snapshots from the second array. Alternatively, one might configure snapshots on the primary array every hour, but only invoke snapshots every four hours on the off-site secondary array -- for longer retention before requiring backups for restoration.
Everything described above (CoW vs. RoW, clones, replication and so on) is specific to the mechanics of individual arrays, but, as mentioned earlier, snapshots are often combined with traditional backup mechanisms for a more agile and comprehensive range of recovery scenarios. Historically, storage administrators exclusively managed many organizations' snapshots using vendor array-specific tools, which were separate from the backup administrator's UIs. Today, many of the leading backup software offerings integrate manageability with mainstream storage products and their snapshotting capabilities. Though the arrays that support integrated manageability vary greatly, as does the integration and extensibility of the snapshot management functions, the more common configurations allow the following:
- A single management UI (the backup console) for configuring the snapshot schedule with policies similar to the way backups are scheduled, resulting in a single point of view for all daily, weekly and monthly recovery points (from backup) and hourly recovery points (from snapshots).
- A single catalog, where the snapshot iterations on primary storage are seen as simply another source for recoveries, alongside whatever disk, tape or cloud storage the backup software uses natively. That said, there is a great deal of disparity among vendors as to the usability of the catalog, whereby some backup UIs -- coupled with the right storage arrays -- can present indexes of all of the files and their versions within each snap. Other combinations have no visibility into a snap until it is manually mounted by a backup admin.
Restorations (from backups) are rarely enough to meet today's service levels for business units, particularly for core platforms such as databases or virtualization hosts. However, additional technical accommodations must be made for those transactional applications, whereby the storage snapshot vendor provides integration extensions to the database or hypervisor layer, so the snapshot has its data in the most viable state. In doing so, many backup applications can recover individual items from within a snapshot as they can from their own backup storage media, only notably faster, which is the whole point of modernizing one's data protection strategy to begin with.
About the author:
Jason Buffington (@JBuff) is the principal analyst focusing on data protection, preservation and availability with Enterprise Strategy Group (ESG).






