What is data protection and why is it important?
Data protection is the process of safeguarding important information from corruption, compromise or loss.
The importance of data protection increases as the amount of data created and stored continues to grow at unprecedented rates. There is also little tolerance for downtime that can make it impossible to access important information.
Consequently, a large part of a data protection strategy is ensuring that data can be restored quickly after any corruption or loss. Protecting data from compromise and ensuring data privacy are other key components of data protection.
The coronavirus pandemic caused millions of employees to work from home, resulting in the need for remote data protection. Businesses must adapt to ensure they are protecting data wherever employees are, from a central data center in the office to laptops at home.
In this guide, explore what data protection entails, key strategies and trends, and compliance requirements to stay in front of the many challenges of protecting critical workloads.
Principles of data protection
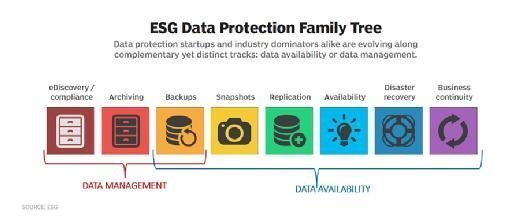
The key principles of data protection are to safeguard and make available data under all circumstances. The term data protection describes both the operational backup of data as well as business continuity/disaster recovery (BCDR). Data protection strategies are evolving along two lines: data availability and data management.
Data availability ensures users have the data they need to conduct business even if the data is damaged or lost.
The two key areas of data management used in data protection are data lifecycle management and information lifecycle management. Data lifecycle management is the process of automating the movement of critical data to online and offline storage. Information lifecycle management is a comprehensive strategy for valuing, cataloging and protecting information assets from application and user errors, malware and virus attacks, machine failure or facility outages and disruptions.
More recently, data management has come to include finding ways to unlock business value from otherwise dormant copies of data for reporting, test/dev enablement, analytics and other purposes.
What is the purpose of data protection?
Storage technologies for protecting data include a disk or tape backup that copies designated information to a disk-based storage array or a tape cartridge. Tape-based backup is a strong option for data protection against cyber attacks. Although access to tapes can be slow, they are portable and inherently offline when not loaded in a drive, and thus safe from threats over a network.
Organizations can use mirroring to create an exact replica of a website or files so they're available from more than one place.
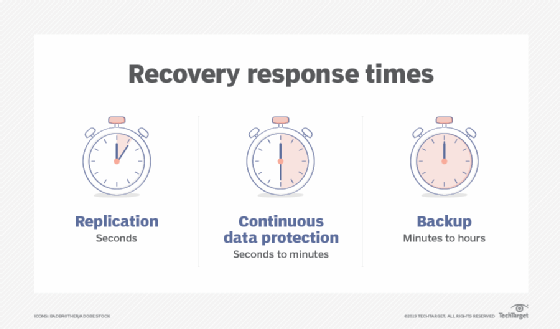
Storage snapshots can automatically generate a set of pointers to information stored on tape or disk, enabling faster data recovery, while continuous data protection (CDP) backs up all the data in an enterprise whenever a change is made.
Data portability
Data portability -- the ability to move data among different application programs, computing environments or cloud services -- presents another set of problems and solutions for data protection. On the one hand, cloud-based computing makes it possible for customers to migrate data and applications among cloud service providers. On the other hand, it requires safeguards against data duplication.
Either way, cloud backup is becoming more prevalent. Organizations frequently move their backup data to public clouds or clouds that backup vendors maintain. These backups can replace on-site disk and tape libraries, or they can serve as additional protected copies of data.
Backup has traditionally been the key to an effective data protection strategy. Data was periodically copied, typically each night, to a tape drive or tape library where it would sit until something went wrong with the primary data storage. That's when organizations would access and use the backup data to restore lost or damaged data.
Backups are no longer a standalone function. Instead, they're being combined with other data protection functions to save storage space and lower costs.
Backup and archiving, for example, have been treated as two separate functions. Backup's purpose was to restore data after a failure, while an archive provided a searchable copy of data. However, that led to redundant data sets. Today, some products back up, archive and index data in a single pass. This approach saves organizations time and cuts down on the amount of data in long-term storage.
The convergence of disaster recovery and backup
Another area where data protection technologies are coming together is in the merging of backup and disaster recovery (DR) capabilities. Virtualization has played a major role here, shifting the focus from copying data at a specific point in time to continuous data protection.
Historically, data backup has been about making duplicate copies of data. DR, on the other hand, has focused on how companies use backups once a disaster happens.
Snapshots and replication have made it possible to recover much faster from a disaster than in the past. When a server fails, data from a backup array is used in place of the primary storage -- but only if an organization takes steps to prevent that backup from being modified.
Those steps involve using a snapshot of the data from the backup array to immediately create a differencing disk. The original data from the backup array is then used for read operations, and write operations are directed to the differencing disk. This approach leaves the original backup data unchanged. And while all this is happening, the failed server's storage is rebuilt, and data is replicated from the backup array to the failed server's newly rebuilt storage. Once the replication is complete, the contents of the differencing disk are merged onto the server's storage and users are back in business.
Data deduplication, also known as data dedupe, plays a key role in disk-based backup. Dedupe eliminates redundant copies of data to reduce the storage capacity required for backups. Deduplication can be built into backup software or can be a software-enabled feature in disk libraries.
Dedupe applications replace redundant data blocks with pointers to unique data copies. Subsequent backups only include data blocks that have changed since the previous backup. Deduplication began as a data protection technology and has moved into primary data as a valuable feature to reduce the amount of capacity required for more expensive flash media.
CDP has come to play a key role in disaster recovery, and it enables fast restores of backup data. Continuous data protection enables organizations to roll back to the last good copy of a file or database, reducing the amount of information lost in the case of corruption or data deletion. CDP started as a separate product category but evolved to the point where it is now built into most replication and backup applications. CDP can also eliminate the need to keep multiple copies of data. Instead, organizations retain a single copy that's updated continuously as changes occur.
Enterprise data protection strategies
Modern data protection for primary storage involves using a built-in system that supplements or replaces backups and protects against the potential problems outlined below.
Media failure. The goal here is to make data available even if a storage device fails. Synchronous mirroring is one approach in which data is written to a local disk and a remote site at the same time. The write is not considered complete until a confirmation is sent from the remote site, ensuring that the two sites are always identical. Mirroring requires 100% capacity overhead.
RAID protection is an alternative that requires less overhead capacity. With RAID, physical drives are combined into a logical unit that's presented as a single hard drive to the operating system. With RAID, the same data is stored in different places on multiple disks. As a result, I/O operations overlap in a balanced way, improving performance and increasing protection.
RAID protection must calculate parity, a technique that checks whether data has been lost or written over when it's moved from one storage location to another. That calculation consumes compute resources.
The cost of recovering from a media failure is the time it takes to return to a protected state. Mirrored systems can return to a protected state quickly; RAID systems take longer because they must recalculate all the parity. Advanced RAID controllers don't have to read an entire drive to recover data when doing a drive rebuild. They only need to rebuild the data that is on that drive. Given that most drives run at about one-third capacity, intelligent RAID can reduce recovery times significantly.
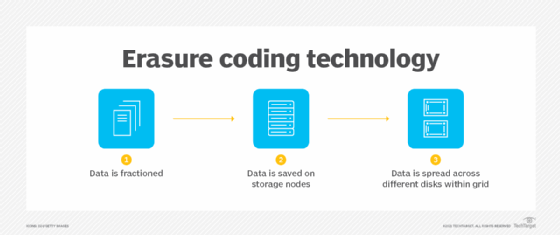
Erasure coding is an alternative to advanced RAID that's often used in scale-out storage environments. Like RAID, erasure coding uses parity-based data protection systems, writing both data and parity across a cluster of storage nodes. With erasure coding, all the nodes in the storage cluster can participate in the replacement of a failed node, so the rebuilding process doesn't get CPU-constrained and it happens faster than it might in a traditional RAID array.
Replication is another data protection alternative for scale-out storage, where data is mirrored from one node to another or to multiple nodes. Replication is simpler than erasure coding, but it consumes at least twice the capacity of the protected data.
Data corruption. When data is corrupted or accidentally deleted, snapshots can be used to set things right. Most storage systems today can track hundreds of snapshots without any significant effect on performance.
Storage systems using snapshots can work with platforms, such as Oracle and Microsoft SQL Server, to capture a clean copy of data while the snapshot is occurring. This approach enables frequent snapshots that can be stored for long periods of time.
When data becomes corrupted or is accidentally deleted, a snapshot can be mounted and the data copied back to the production volume, or the snapshot can replace the existing volume. With this method, minimal data is lost and recovery time is almost instantaneous.
Storage system failure. To protect against multiple drive failures or some other major event, data centers rely on replication technology built on top of snapshots.
With snapshot replication, only blocks of data that have changed are copied from the primary storage system to an off-site secondary storage system. Snapshot replication is also used to replicate data to on-site secondary storage that's available for recovery if the primary storage system fails.
Full-on data center failure. Protection against a data center loss requires a full DR plan. As with the other failure scenarios, organizations have multiple options. One option is snapshot replication, which replicates data to a secondary site. However, the cost of running a secondary site can be prohibitive.
Cloud services are another alternative. An organization can use replication along with cloud backup products and services to store the most recent copies of crucial data in the event of a major disaster and to instantiate application images. The result is a rapid recovery in the event of a data center loss.
Data protection trends
Though research shows that it's important to stay in front of these latest trends in data protection policy and technology.
Hyper-convergence. With the advent of hyper-convergence, vendors have started offering appliances that provide backup and recovery for physical and virtual environments that are hyper-converged, non-hyper-converged and mixed. Data protection capabilities integrated into hyper-converged infrastructure are replacing a range of devices in the data center.
Cohesity, Rubrik and other vendors offer hyper-convergence for secondary storage, providing backup, DR, archiving, copy data management and other nonprimary storage functions. These products integrate software and hardware, and they can serve as a backup target for existing backup applications in the data center. They can also use the cloud as a target and provide backup for virtual environments.
Ransomware. This type of malware, which holds data hostage for an extortion fee, is a growing problem. Traditional backup methods have been used to protect data from ransomware. However, more sophisticated ransomware is adapting to and circumventing traditional backup processes.
The latest version of the malware slowly infiltrates an organization's data over time, so the organization ends up backing up the ransomware virus along with the data. This situation makes it difficult, if not impossible, to roll back to a clean version of the data.
To counter this problem, vendors are working on adapting backup and recovery products and methodologies to thwart the new ransomware capabilities.
In addition, businesses must make sure they protect data stored remotely, as ransomware threats are amplified when employees are more vulnerable and operate on less secure networks.
Copy data management. CDM cuts down on the number of copies of data an organization must save, reducing the overhead required to store and manage data and simplifying data protection. CDM can speed up application release cycles, increase productivity and lower administrative costs through automation and centralized control.
The next step with CDM is to add more intelligence. Companies such as Veritas Technologies are combining CDM with their intelligent data management platforms.
Disaster recovery as a service. DRaaS use is expanding as more options are offered and prices come down. It's being used for critical business systems where an increasing amount of data is being replicated rather than just backed up.
Mobile data protection
Among common data protection challenges, backup and recovery for mobile devices is tough. It can be difficult to extract data from these devices, and inconsistent connectivity makes scheduling backups difficult -- if not impossible. And mobile data protection is further complicated by the need to keep personal data stored on mobile devices separate from business data.
Selective file sync and share is one approach to data protection on mobile devices. While it isn't true backup, file sync-and-share products typically use replication to sync users' files to a repository in the public cloud or on an organization's network. That location must then be backed up. File sync and share does give users access to the data they need from a mobile device while synchronizing any changes they make to the data with the original copy. However, it doesn't protect the state of the mobile device, which is needed for quick recovery.
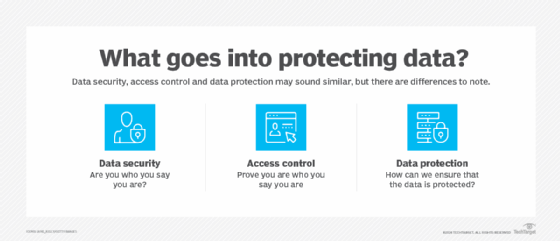
Differences between data protection, security and privacy
Although some businesses use the terms data protection, data security and data privacy, they have different purposes:
- Data protection safeguards information from loss through backup and recovery.
- Data security refers specifically to measures taken to protect the integrity of the data itself against manipulation and malware. It provides defense from internal and external threats.
- Data privacy refers to controlling access to the data. Organizations must determine who has access to data. Understandably, a privacy breach can lead to data security issues.
Data protection and privacy laws
Data protection and privacy laws and regulations vary from country to country, and even from state to state -- and there's a constant stream of new ones. China's data privacy law went into effect June 1, 2017. The European Union's General Data Protection Regulation (GDPR) went into effect in 2018. In the United States, the California Consumer Privacy Act supports the right for individuals to control their own personally identifiable information. Compliance with any one set of rules is complicated and challenging.

Coordinating among all the disparate rules and regulations is a massive task. Being out of compliance can mean steep fines and other penalties, including having to stop doing business in the country or region covered by the law or regulation.
For a global organization, experts recommend having a data protection policy that complies with the most stringent set of rules the business faces, while at the same time using a security and compliance framework that covers a broad set of requirements. The guidelines for data protection and privacy apply across the board and include the following:
- safeguarding data;
- getting consent from the person whose data is being collected;
- identifying the regulations that apply to the organization and the data it collects; and
- ensuring employees are fully trained in the nuances of data privacy and security.
Data protection for GDPR compliance
The European Union updated its data privacy laws with a directive that went into effect May 25, 2018. The GDPR replaces the EU Data Protection Directive of 1995 and focuses on making businesses more transparent. It also expands privacy rights with respect to personal data.
The GDPR covers all EU citizens' data regardless of where the organization collecting the data is located. It also applies to all people whose data is stored within the European Union, whether they are EU citizens or not.
GDPR compliance requirements include the following:
- Barring businesses from storing or using an individual's personally identifiable information without that person's express consent.
- Requiring companies to notify all affected people and the supervising authority within 72 hours of a data breach.
- For businesses that process or monitor data on a large scale, having a data protection officer who's responsible for data governance and ensuring the company complies with GDPR.
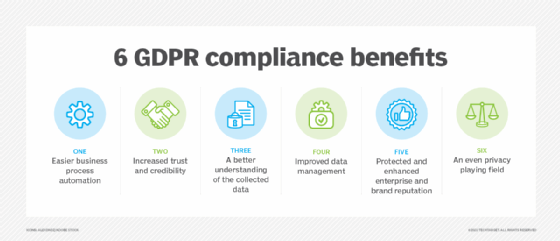
Organizations must comply with GDPR or risk fines as much as 20 million euros or 4% of the previous fiscal year's worldwide turnover, depending on which is larger.
The GDPR, in Recital 1, notes that the protection of personal data is a fundamental right. However, in Recital 4, it says that this right must be balanced with other rights.
Recital 1 states: "The protection of natural persons in relation to the processing of personal data is a fundamental right. Article 8(1) of the Charter of Fundamental Rights of the European Union (the 'Charter') and Article 16(1) of the Treaty on the Functioning of the European Union (TFEU) provide that everyone has the right to the protection of personal data concerning him or her."
Recital 4 states: "The processing of personal data should be designed to serve mankind. The right to the protection of personal data is not an absolute right; it must be considered in relation to its function in society and be balanced against other fundamental rights, in accordance with the principle of proportionality. This Regulation respects all fundamental rights and observes the freedoms and principles recognized in the Charter as enshrined in the Treaties, in particular the respect for private and family life, home and communications, the protection of personal data, freedom of thought, conscience and religion, freedom of expression and information, freedom to conduct a business, the right to an effective remedy and to a fair trial, and cultural, religious and linguistic diversity."






