data reduction
What is data reduction?
Data reduction lowers the amount of capacity required to store data. Data reduction can increase storage efficiency and reduce costs.
Data reduction can be achieved several ways. The main types are data deduplication, compression and single-instance storage. Data deduplication, also known as data dedupe, eliminates redundant segments of data on storage systems. It only stores redundant segments once and uses that one copy whenever a request is made to access that piece of data. Data dedupe is more granular than single-instance storage. Single-instance storage finds files such as email attachments sent to multiple people and only stores one copy of that file. As with dedupe, single-instance storage replaces duplicates with pointers to the one saved copy.
Some storage arrays track which blocks are the most heavily shared. Those blocks that are shared by the largest number of files may be moved to a memory- or flash storage-based cache so they can be read as efficiently as possible.
Data compression also works on a file level. It is accomplished natively in storage systems using algorithms or formulas designed to identify and remove redundant bits of data. Data compression specifically refers to a data reduction method by which files are shrunk at the bit level.
Compression works by using formulas or algorithms to reduce the number of bits needed to represent the data. This is usually done by representing a repeating string of bits with a smaller string of bits and using a dictionary to convert between them.
Common techniques of data reduction
There are also ways to reduce the amount of data that must be stored without shrinking the sizes of blocks and files. These techniques include thin provisioning and data archiving.
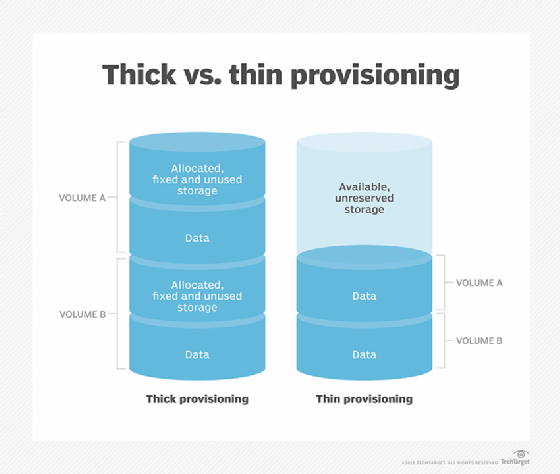
Thin provisioning dynamically allocates storage space in a flexible manner. This method keeps reserved space just a little ahead of actual written space, enabling more unreserved space to be used by other applications.
thick provisioning allocates fixed amounts of storage space as soon as a disk is created, regardless of whether that entire capacity will be filled.
Archiving data also reduces data on storage systems, but the approach is quite different. Rather than reducing data within files or databases, archiving removes older, infrequently accessed data from expensive storage and moves it to low-cost, high-capacity storage. Archive storage can be on disk, tape or cloud.
Data reduction for primary storage
Although data deduplication was first developed for backup data on secondary storage, it is possible to deduplicate primary storage. Primary storage deduplication can occur as a function of the storage hardware or operating system (OS). Windows Server 2012 and Windows Server 2012 R2, for instance, have built-in data deduplication capabilities. The deduplication engine uses post-processing deduplication, which means deduplication does not occur in real time. Instead, a scheduled process periodically deduplicates primary storage data.
Primary storage deduplication is a common feature of many all-flash storage systems. Because flash storage is expensive, deduplication is used to make the most of flash storage capacity. Also, because flash storage offers such high performance, the overhead of performing deduplication has less of an impact than it would on a disk system.







